

Hello everyone! If you haven’t checked out part 1 to this series, I recommend giving it a quick read!
A quick introduction for those that decide to skip part 1:
VetSecs current mission focus is to help train current military veterans on the basics of Cybersecurity and help guide them in this field. It is an organization that is filled with people from complete beginner to highly professional. If you’re a veteran and would like to join, feel free to swing by our slack channel!
To help aid in training veterans, I have begun working on our very own Wargame, which will provide tutorials and challenges for those who are interested. Creating a Wargame is completely new to me, so I hope to learn a lot from this process while providing others with insight to learn alongside me.
This post will be focused on my work on the framework of the Wargame and a very rough creation of my first challenge. There was a lot of learning in this process, as I have not had write too many BASH scripts before as well as ensuring everything needed by the user was easily accessible.
What I learned:
- BASH: I had to learn a bit of BASH scripting for this process to automate a lot of the setting up of the VM. This is something I will definitely have to get better at, so I hope to try and work on this more as I go along!
- Makefiles: I wanted to learn something new while I created these challenges and Makefiles are one way to automate the compiling process of binaries. They can be very useful for very extensive programs that require a bunch of files and dependencies. I definitely don’t go too deep into them in this, just a light intro.
- Buffer Overflow challenge creation: After always working on challenges that required buffer overflows to be accomplished, it was nice to see it from a developers viewpoint, and I will continue this learning process in the next blog post that I write!
Helpful links/resources:
Tweaking the Wargame VM:
After setting up a bit more of the Wargame and trying to make sure everything would work correctly, I realized that I wanted to change the structure a little bit. I really wanted to separate the Vagrantfile from any future tweaking of provisioning that I do. To do this, I made a bash script to be called when Vagrant begins to provision the box.

Updating the Vagrantfile to provision with a BASH Script
The only changes here that I made from what I did in part 1, was at Line 23, with ‘shell.inline = “bash /vagrant/setup_box.sh”‘. This will now run my BASH script which installs the required packages/tools and puts the challenges into the proper locations. The script can be seen below or downloaded from my Github.
A WHOLE LOTTA BASH:

The setup_box.sh script that provisions the VM
A quick description of this script to help those who don’t know BASH (I had no prior experience to it before writing this).
- The first line is the basic ‘shebang‘ that tells the shell to execute this script using bash. You have to provide the full path to the bash shell here.
- Lines 4-11: This is a function I made to push all of the challenges and scripts from the default location into the home directory for ease of access. This will likely be changed later to remove the lingering folders (once I figure out how this whole thing works better)
- Lines 13-32: This function installs the required packages and tools that will be needed for the challenges. Line 16 installs gcc a compiler used for compiling C programs. Line 17 and 18 install PEDA and radare2. PEDA is used to help with exploitation development during debugging with GDB. Radare2 is a command line disassembler that will assist with reverse engineering challenges. Lines 20-26 uses $PWD which is an environment variable that expands to the current working directory. It then runs a for loop through each of the tools directories and checks if a file called ‘configure‘ (via the -e for exists, in side of the [ ] on Line 21) is located in the directory. It then sets up the tools via their configuration script and make files. Line 28 is required for PEDA to be used in GDB. Line 29 tweaks the VIM text editor to have numbered lines and tabs that are 4 spaces long.
- Lines 34-44: This function sets up each of the challenges via a makefile located in each challenge folder. Makefiles are used for making a single script to compile all needed dependencies and header files. I used this website to help me create mine and I’ll explain an example one in a later part of this post. Line 39 uses an interesting thing called a Parameter Expansion. This combination expands argument 0 ($0), which is the name of our script, not a real argument. The curly braces { and } work with the expansion and allow us to use %/*. What this does is it matches the last occurrence of the character following the %, so in our case, it matches a /, and then removes anything (* means anything) after that character. This gives us the ability to change directories directly into the challenge folder and then (&& means and also) run the makefile via the ‘make‘ command, while in that directory. This is necessary because makefiles often create a file that will be placed in the directory that is currently being worked from, then often require that file for another step. If this file is not placed in the same location as the makefile, it can lead to an error.
- Lines 50-52: This is the body of the script, which just calls each function that I previously described.
That was a lot of BASH! If you aren’t familiar with BASH, it is a scripting language that the BASH Shell inside of linux can use to automate tasks that could normally be completed via the terminal. It is extremely useful for doing a lot of work in a single swoop, as you can see from everything I explained above that a single file just did for me.
Creating the first challenge:
This first challenge is a direct adaptation of the first challenge in Protostar, which is a very basic buffer overflow. The goal is to modify a variable that is created by overflowing a buffer and overwriting the memory location that holds what is stored in the variable. I will be creating a more in depth tutorial for how this whole process works in a future blog post, but for now, we need to create the challenge!
The Source Code

Source code for bufferoverflow.c
I won’t go into too much detail for this challenge as it deserves an entire post of its own. If you are not familiar with C Programming, it is one of the first major programming languages that began development back in 1968 at Bell Labs. It is very versatile and it is widely used still, even to this day! In fact, it’s what the Linux kernel is written in! For a great introduction to C Programming and Exploitation Development, I would recommend checking out the book, Hacking: The Art of Exploitation.
Buffer overflow from a programmers perspective:
I’ll provide a quick overview of the program source code:
- Line 1: This is what is known as an include directive. This one in particular includes the header file called stdio.h (the .h is for header file). A header file includes a bunch of function declarations that we can use in our program without the need to rewrite or define them. In particular, ‘stdio.h‘ provides us with input and output functionality, which is where the ‘gets()‘ function in this challenge is declared.
- Line 3: This is the main function of the program, which must return an integer, as defined in the C Standard. The ‘int‘ (Which stands for integer) in front of the word main determines what type of value is returned by the function being defined/declared. There are no arguments provided for this function as can be seen by nothing in between the parenthesis after the word ‘main‘.
- Lines 5-8: This starts by creates a variable called ‘modified’, which is an integer data type and volatile. Volatile just means that the variable may change after compilation, which we will want to ensure for this challenge. Then we create a ‘char array‘ of size 64 bytes called ‘buffer‘. Char stands for character, and is another data type, like integer, but is intended to hold alphabet characters. An array is a group of bytes in memory that are contiguous and one of the most basic data structures. We then set modified to 0, just to make sure there is no random data in it.
- Lines 10-11: First, we have a very common function from stdio.h called ‘printf‘ which prints a string of characters to stdout (default is terminal in linux). All prints must end with the escape sequence ‘\n‘ (which means line feed, and will print anything after it to the next line) in C programming in order to guarantee that the statement will be printed to the terminal and not interfered with, due to C programming being line buffered. The next function is ‘gets‘, also from stdio.h, which will wait for and get the input that a user puts into stdin (which is the terminal by default in linux). The gets function takes an argument, which is the location that the input will be stored, after it is received. This is why the ‘buffer‘ variable is in between the parenthesis after gets. So essentially, we are filling the buffer variable with our input from the terminal.
- Line 13-19: We use a standard if statement for comparing the variable ‘modified‘ to 0. In this case, we use ‘!=‘, which means ‘not equal to‘. So if our variable ‘modified‘ is not equal to 0 (the original value we set it to), then the statement “You modified the variable” will be printed. Otherwise, if the ‘modified‘ variable is equal to 0, it will print “You did not manage to modify the variable. Try again.“, to the terminal, and then the program will exit.
Now, I know this may be a lot, but don’t worry, I’ll go deeper in a future post. This was just a light intro to what a buffer overflow looks like in a C program. Next time, we will view it from a computers perspective.
The makefiles:
When programming as a beginner, you will likely develop programs using an IDE (integrated development environment). These help abstract the compiling process from you and give you a nice environment with features that will assist you with programming. When you are forced to use just the command line for this, it can be a bit of a burden to compile files. One solution is a makefile, which allows you to automate these commands and simply just type ‘make‘ in the command prompt. I decided to use this so I could learn more about them while I develop these challenges and you can see my first one below!
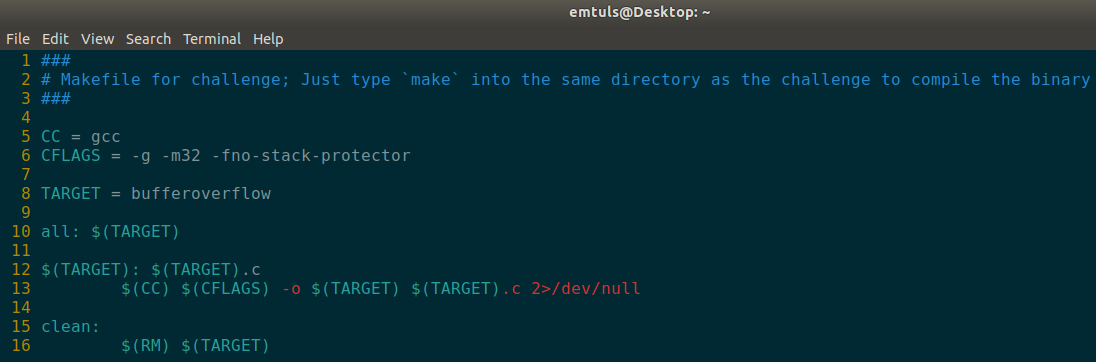
The makefile for bufferoverflow.c
Explanation
This is not something you will likely have to work with, unless you are a developer, so don’t feel in the dark if you don’t understand this. I used this for reference.
- Line 5: I set a variable called CC to ‘gcc‘, which means we will be using the gcc compiler to compile this program.
- Line 6: I set a variable called CFLAGS to ‘-g -m32 -fno-stack-protector‘ which are the flags I want the program to be compiled with. The ‘-g‘ flag will allow for more debug information provided with the file, the ‘-m32‘ flag will compile this program into a 32bit binary, and the ‘-fno-stack-protector‘ will disable stack canaries, which is a buffer overflow protection that I will explain in a future post.
- Line 8: I set a variable called TARGET to ‘bufferoverflow‘, which is the name of the challenge program to be compiled.
- Line 10: the all means to create all file we associate with it, a better explanation is here. I use $(TARGET) to enumerate the variable, TARGET that I set earlier.
- Line 12-13: This is wear the magic happens. Line 12 is a bit obscure and I don’t fully understand yet and Line 13 we begin the compilation process. We enumerate all of our variables, so it becomes ‘gcc -g -m32 -fno-stack-protector -o bufferoverflow bufferoverflow.c 2>/dev/null‘. This means to use GCC to compile our program, ‘bufferoverflow.c‘ with the flags ‘g -m32 -fno-stack-protector‘. The -o means to make our compiled file an object file called just ‘bufferoverflow‘, without an extension, for ease of executing. The ‘2>/dev/null‘ is used because compiling this program spits out a few warnings due to the nature of how insecure the functions we are using are.
- Line 15-16: This is just used for a simple cleanup. It will remove (with linux command rm) the target file, but leave our original ‘bufferoverflow.c‘ file, so we can recompile it again later.
Extra (Toggling ASLR for challenges)
I decided to turn off ASLR (Address Space Layout Randomization) for the intro challenges, and to do this, I made a simple script to both make/compile the binary and either turn off or on ASLR, depending on what it should be set to for the challenge. The setup files for each challenge should be run as ‘sudo‘, like such: ‘sudo ./setup‘. This will both compile the binary and turn on/off options, as well as implement other things I might decide to add at a later time. The script can be seen below for the first challenge. 
Explanation
- Line 11-12: I set a variable called ‘aslr‘ whether ASLR should be on or off. I also set a variable to another Parameter Expansion, which leaves us with just the ‘basename’ (like ‘bufferoverflow‘ for example) of the folder we are running the script from, which should be the challenge name, if I continue to follow a standard convention.
- Lines 14-20: This is a function called ‘setup‘ that just calls a script I made to toggle ASLR via a command depending on the value of the argument I pass to the script. In this case, at Line 15, I pass the script ‘off’, so it will turn off ASLR via this command. A picture of the script can be seen below, after this explanation. Line 17 checks if the file has already been compiled by looking for a file just named what is set to the variable ‘challenge‘. Which in this case, it would look for a file called ‘bufferoverflow‘, and if it exists, it won’t run make, but if it does not exist, it will run ‘make‘, which runs the make file I explained before, to compile the binary.
- Line 22: This is the main part of the script, which simply calls the setup function to do all of the work.
ASLR toggle script
As mentioned earlier, each of my challenges has a setup file that is required to be run before each challenge that will set up the required environment. One of these requirements will be for ASLR to be turned off, so we can focus on just the basics of a buffer overflow. So for this, the setup file may call this script with an argument as to whether it should toggle ASLR on or off. The script can be seen below.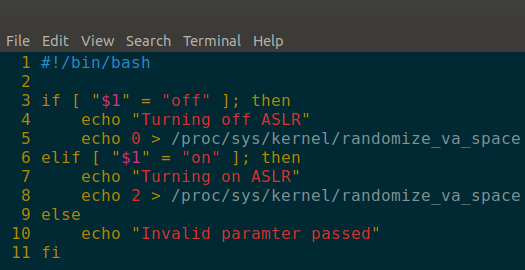
Explanation
- I went over it briefly in the last script, but this script expects an argument that should resolve to ‘off‘ or ‘on‘. Depending on which value is passed to the script, it will run the command following command:
echo 0 > /proc/sys/kernel/randomize_va_space
or
echo 2 > /proc/sys/kernel/randomize_va_space
The 0 is to turn off ASLR and the 2 is to turn it back on
I hope this was a useful tutorial and/or learning opportunity for you guys! If you have any feedback or want to chat, feel free to contact me on one of my many means of communication. Thanks!
If you’re a veteran interested in Cyber Security, consider joining our Slack channel.
[…] Wargame, but I was finally able to find some time! Again, if you haven’t followed my other two blog posts, this post may not make a lot of sense, so I highly recommend at least skimming them if […]
[…] ‘makefile‘ is a file that I explain in my second post on creating the VetSec VM here and here. What this is used for, is a way for me to automate the commands required to compile my c […]